
Introduction
Transformers have revolutionized the field of Natural Language Processing (NLP) and have become the backbone of modern Large Language Models (LLMs) like GPT-4, BERT, and T5. In this blog, we will explore how transformers work, their architecture, and their role in powering AI-driven applications.
What Are Transformers?
Transformers are a type of deep learning model designed for sequence-to-sequence tasks, such as translation, text generation, and question answering. Unlike traditional models like RNNs, transformers use self-attention mechanisms to process words in parallel, making them highly efficient.
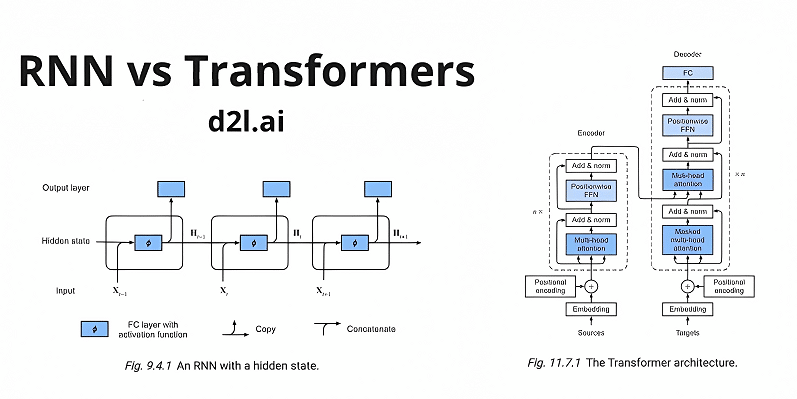
The Architecture of Transformers
A transformer consists of two main components:
- Encoder: Processes the input sequence and generates context-aware representations.
- Decoder: Generates the output sequence based on the encoded input.
Each component contains multiple layers of self-attention and feedforward neural networks.
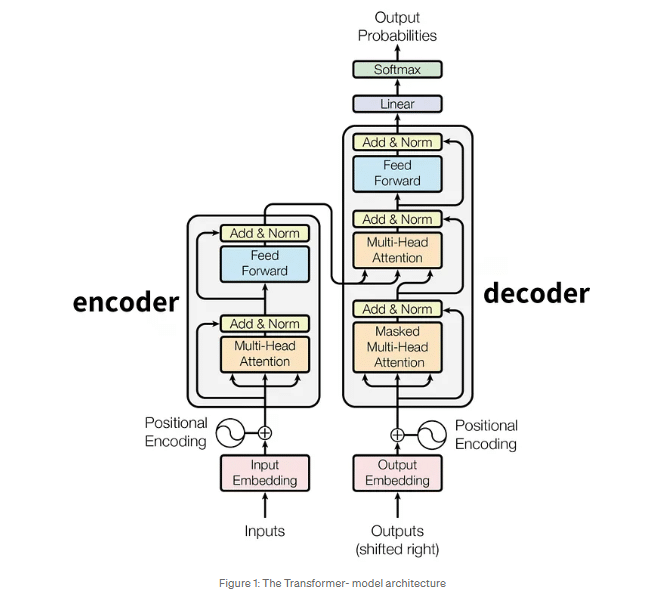
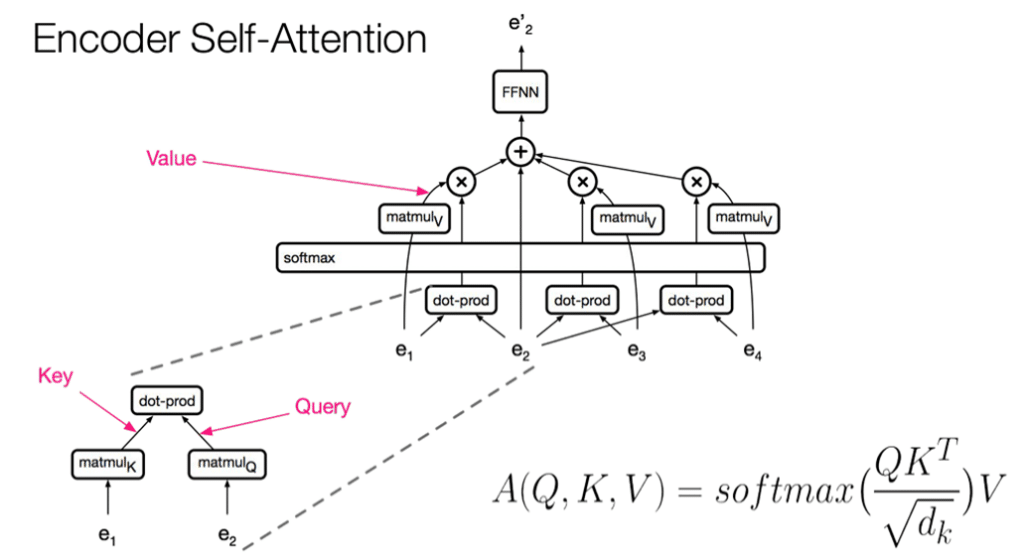
Self-Attention Mechanism
The self-attention mechanism allows the model to weigh different words in a sentence based on their relevance. This is crucial for understanding contextual relationships between words.
Formula for self-attention: Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{softmax} \left(\frac{QK^T}{\sqrt{d_k}} \right) V Where:
- QQ (Query), KK (Key), and VV (Value) are the input representations.
- dkd_k is the dimension of the key vector.
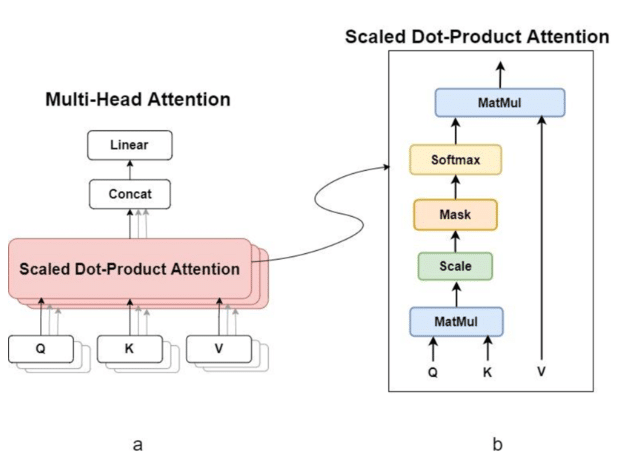
Multi-Head Attention
Transformers use multiple attention heads to capture different aspects of word relationships simultaneously.
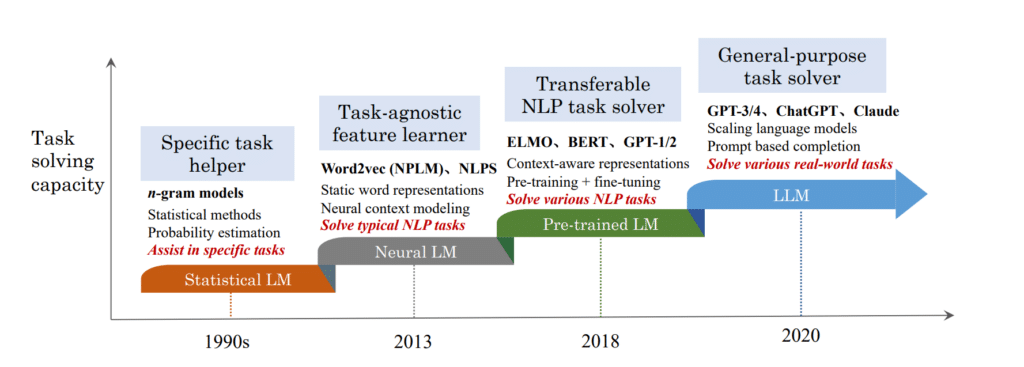
Large Language Models (LLMs) and Their Evolution
LLMs are built on transformer architectures and trained on massive datasets to perform various NLP tasks. Some key LLMs include:
- BERT (Bidirectional Encoder Representations from Transformers): Pre-trained using masked language modeling.
- GPT (Generative Pre-trained Transformer): Focuses on autoregressive text generation.
- T5 (Text-To-Text Transfer Transformer): Converts NLP tasks into a text-to-text format.
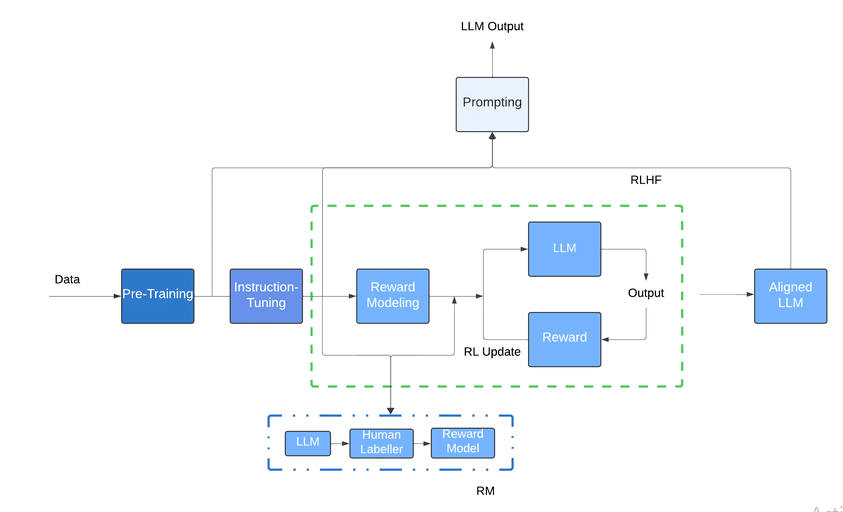
How LLMs Process Text
- Tokenization: Converts text into smaller units (tokens).
- Embedding: Transforms tokens into numerical vectors.
- Attention Mechanism: Determines the importance of each token.
- Feedforward Networks: Process the contextualized data.
- Output Generation: Produces the final text output.
Applications of LLMs
LLMs are used in various applications, including:
- Chatbots and Virtual Assistants: (e.g., ChatGPT, Google Assistant)
- Automated Content Generation: (e.g., AI-powered article writing)
- Language Translation: (e.g., Google Translate)
- Code Generation (e.g., GitHub Copilot)
- Summarization and Sentiment Analysis
Challenges and Ethical Concerns
Despite their capabilities, LLMs face challenges such as:
- Bias in Training Data: AI models may inherit biases from their datasets.
- High Computational Costs: Training and running LLMs require significant resources.
- Misinformation and Hallucination: LLMs sometimes generate incorrect or misleading information.
- Privacy Concerns : Handling sensitive data poses ethical issues.
Future of Transformers and LLMs
Transformers continue to evolve, with research focused on:
- More efficient models: (e.g., smaller yet powerful LLMs like GPT-4-turbo)
- Better interpretability: (understanding how models make decisions)
- Multimodal AI: (combining text, images, and videos)
- Energy-efficient training methods
Conclusion
Transformers and Large Language Models have reshaped AI and NLP, powering a wide range of applications. As research progresses, we can expect even more innovative and ethical AI solutions in the future.